Introduction
This analysis is of a new winlocker dropper that was first seen in the wild last month, the binary is 64 bit, packed with MPRESS, and contains 3 local privilege escalation exploits (CVE-2013-3660, CVE-2012-1864, and CVE-2012-0217), as well as the PowerLoader injection method. 2 of the exploits and the powerloader injection were stolen from carberp leak. I, as well as a few others, thought the dropper may be PowerLoader, however I now have my doubts, I will explain why at the end.
Data Gathering
The first thing the loader does is query some system information, then post it to the command and control server (C&C).
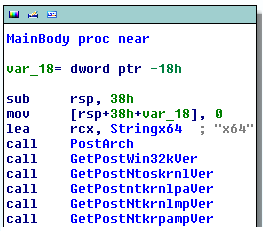
The function I have named "PostArch" simply posts the string "x64" to the C&C, the rest of the functions query the version information of the following file: win32k.sys, ntoskrnl.exe, ntkrnlpa.exe, ntkrnlmp.exe, and ntkrpamp.exe, then post it to the command and control.

The first header is for the "PostArch" function, the second is for the rest. Any data is url encoded so the file version data is "f=win32k.sys&v=6.1.7600.16617&", this format is used for every file and the last "&" doesn't do anything but the coder appends it anyway.
Exploitation
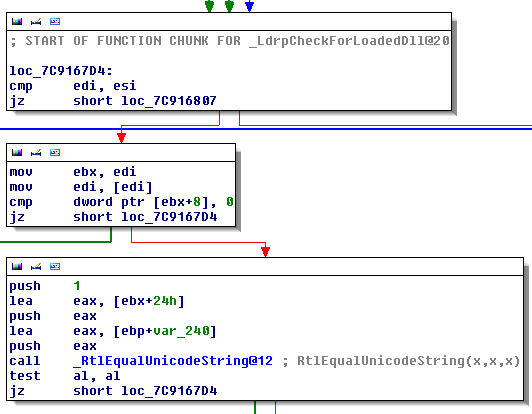
The loader will inject into explorer using an x64 version of the infamous Shell_TrayWnd Injection (Explained Here). Once inside explorer the first exploit is executed, if it fail: the next one is executed, and so on.
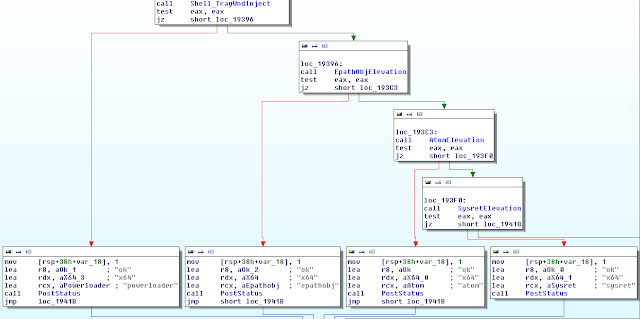 |
| The code flow of the elevation attempt |
The exploits are as follows:
- EPATHOBJ::pprFlattenRec (CVE-2013-3660)
- String Atom Class Name (CVE-2012-1864)
- (Intel / x64) SYSRET (CVE-2012-0217)
Each exploit will try to elevate the process privileges, if successful, a dll will be written to the temporary directory, under the name "dll.dll", then executed (The dll is also packed with MPRESS).
Let's take take a look at the dll after unpacking.
 |
| The real entry point of the packed dll |
Let's take a look at what is does with this value.
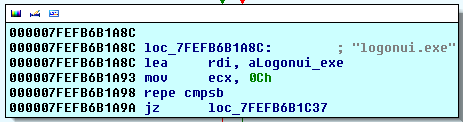 |
| First check (Are we in logonui process) |
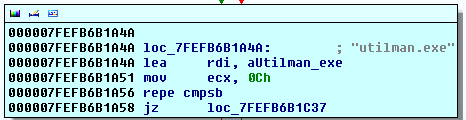 |
| Second check (Are we in utilman process) |
 |
| The jump destination if we are inside utilman or logonui |

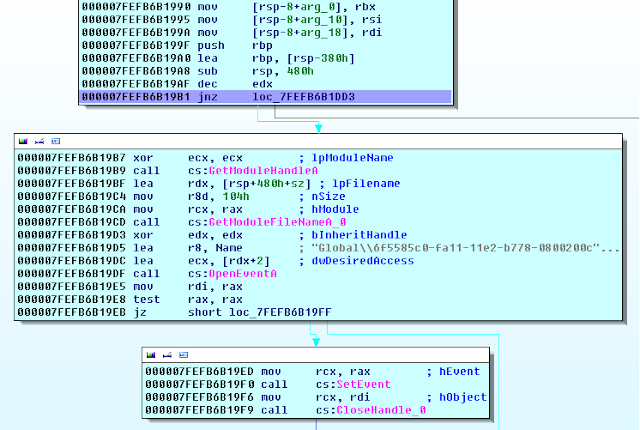
This is the last stage, here the dll extracts and drops a second dll to "C:\Windows\System32\vBszKyhVp.dll". The loader then looks for an svchost process running as "NETWORK SERVICE", opens a handle to the process, allocates some memory inside, writes the dll path to the allocated memory, and calls "RtlCreateUserThread". The thread start address is set to the address of "LoadLibrary" and the parameter set to address of the allocated memory, as a result the thread in svchost will call loadlibrary with the dll path set to the path of the dropped dll, which will cause the process to load the dll.
The 2nd dll is responsible for downloading some images and installing a winlocker, it is also packed with MPRESS, I'll probably reverse it and write about it in a part 2.
![]()
The 2nd dll is responsible for downloading some images and installing a winlocker, it is also packed with MPRESS, I'll probably reverse it and write about it in a part 2.
Why I'm not sure this is PowerLoader
Basically the code seems too closely related, the first dropper creates an event that is then signaled by the 1st dll that is dropped, the dll also checks what process it is in, which could change based on which exploit was successful. The way that the dll interacts with the dropper makes me think that they were both coded by the same person. As well as this, the dropper sets a registry key with the screen resolution, which is used by the locker to get the correct size screen-lock image, this rules out the 1st dll being part of the PowerLoader dropper.
Originally, what made me think it was PowerLoader was the string that said "powerloader".

After a while reversing this sample, I realized that the string is probably just referring to the elevation method used, seeming as this code indicates which method was successful (atom exploit, sysret exploit, epathobj exploit, powerloader injection). To me, it seems more likely that this is all part of the same project and most of the primary dropper code was stolen from carberp.
These 2 images make me think the coders are in the process of implementing a user account control bypass, there is a public bypass that exploit auto-elevating processes on windows 7 (sysprep being one of them). Also, earlier in the article i showed 2 checks (one for logonui.exe and one for utilman.exe). The atom exploit (CVE-2012-1864) will result in the dll getting loaded into logonui process, however, none of the exploits seem to load the dll into utilman, which leads me to think they were testing another exploit.
Possibly more exploits to come
I did notice a few bits of unused code in the dropper that seemed to imply more exploits were on the way.
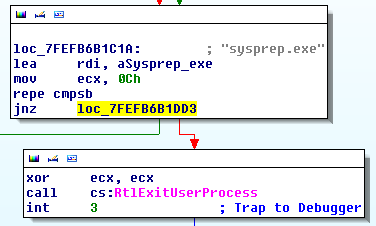 |
| Checking if the process is sysprep then exiting |
 |
| Exports for UAC Injection |
Conclusion
The Shell_TrayWnd Injection and CVE-2012-1864 + CVE-2012-0217 were both taken from the carberp leak (this is probably the biggest theft of code from the leak that i have seen so far). Because the winlocker component seems interesting, I will likely write a part 2 and reverse it.
Thanks to R136a1 for the sample and collaboration on reversing. :)